11 KiB
5.5 污点分析
基本原理
污点分析是一种跟踪并分析污点信息在程序中流动的技术。在漏洞分析中,使用污点分析技术将所感兴趣的数据(通常来自程序的外部输入)标记为污点数据,然后通过跟踪和污点数据相关的信息的流向,可以知道它们是否会影响某些关键的程序操作,进而挖掘程序漏洞。即将程序是否存在某种漏洞的问题转化为污点信息是否会被 Sink 点上的操作所使用的问题。
污点分析常常包括以下几个部分:
- 识别污点信息在程序中的产生点(Source点)并对污点信息进行标记
- 利用特定的规则跟踪分析污点信息在程序中的传播过程
- 在一些关键的程序点(Sink点)检测关键的操作是否会受到污点信息的影响
举个例子:
[...]
scanf("%d", &x); // Source 点,输入数据被标记为污点信息,并且认为变量 x 是污染的
[...]
y = x + k; // 如果二元操作的操作数是污染的,那么操作结果也是污染的,所以变量 y 也是污染的
[...]
x = 0; // 如果一个被污染的变量被赋值为一个常数,那么认为它是未污染的,所以 x 转变成未污染的
[...]
while (i < y) // Sink 点,如果规定循环的次数不能受程序输入的影响,那么需要检查 y 是否被污染
然而污点信息不仅可以通过数据依赖传播,还可以通过控制依赖传播。我们将通过数据依赖传播的信息流称为显式信息流,将通过控制依赖传播的信息流称为隐式信息流。
举个例子:
if (x > 0)
y = 1;
else
y = 0;
变量 y 的取值依赖于变量 x 的取值,如果变量 x 是污染的,那么变量 y 也应该是污染的。
通常我们将使用污点分析可以检测的程序漏洞称为污点类型的漏洞,例如 SQL 注入漏洞:
String user = getUser();
String pass = getPass();
String sqlQuery = "select * from login where user='" + user + "' and pass='" + pass + "'";
Statement stam = con.createStatement();
ResultSetrs = stam.executeQuery(sqlQuery);
if (rs.next())
success = true;
在进行污点分析时,将变量 user 和 pass 标记为污染的,由于变量 sqlQuery 的值受到 user 和 pass 的影响,所以将 sqlQuery 也标记为污染的。程序将变量 sqlQuery 作为参数构造 SQL 操作语句,于是可以判定程序存在 SQL 注入漏洞。
使用污点分析检测程序漏洞的工作原理如下图所示:
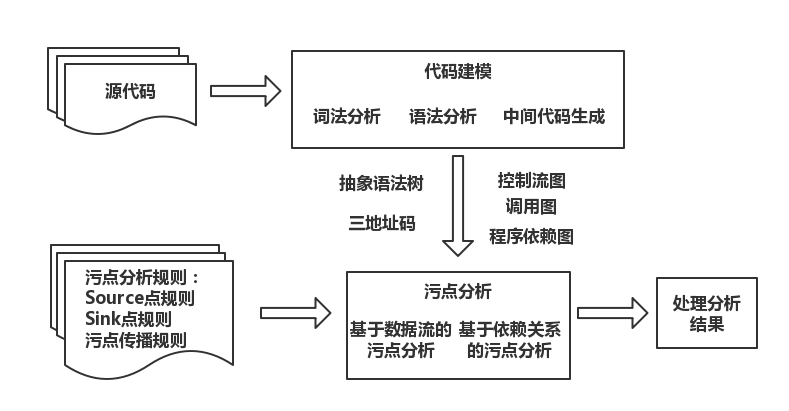
- 基于数据流的污点分析。在不考虑隐式信息流的情况下,可以将污点分析看做针对污点数据的数据流分析。根据污点传播规则跟踪污点信息或者标记路径上的变量污染情况,进而检查污点信息是否影响敏感操作。
- 基于依赖关系的污点分析。考虑隐式信息流,在分析过程中,根据程序中的语句或者指令之间的依赖关系,检查 Sink 点处敏感操作是否依赖于 Source 点处接收污点信息的操作。
方法实现
静态污点分析系统首先对程序代码进行解析,获得程序代码的中间表示,然后在中间表示的基础上对程序代码进行控制流分析等辅助分析,以获得需要的控制流图、调用图等。在辅助分析的过程中,系统可以利用污点分析规则在中间表示上识别程序中的 Source 点和 Sink 点。最后检测系统根据污点分析规则,利用静态污点分析检查程序是否存在污点类型的漏洞。
基于数据流的污点分析
在基于数据流的污点分析中,常常需要一些辅助分析技术,例如别名分析、取值分析等,来提高分析精度。辅助分析和污点分析交替进行,通常沿着程序路径的方向分析污点信息的流向,检查 Source 点处程序接收的污点信息是否会影响到 Sink 点处的敏感操作。
过程内的分析中,按照一定的顺序分析过程内的每一条语句或者指令,进而分析污点信息的流向。
- 记录污点信息。在静态分析层面,程序变量的污染情况为主要关注对象。为记录污染信息,通常为变量添加一个污染标签。最简单的就是一个布尔型变量,表示变量是否被污染。更复杂的标签还可以记录变量的污染信息来自哪些 Source 点,甚至精确到 Source 点接收数据的哪一部分。当然也可以不使用污染标签,这时我们通过对变量进行跟踪的方式达到分析污点信息流向的目的。例如使用栈或者队列来记录被污染的变量。
- 程序语句的分析。在确定如何记录污染信息后,将对程序语句进行静态分析。通常我们主要关注赋值语句、控制转移语句以及过程调用语句三类。
- 赋值语句。
- 对于简单的赋值语句,形如
a = b这样的,记录语句左端的变量和右端的变量具有相同的污染状态。程序中的常量通常认为是未污染的,如果一个变量被赋值为常量,在不考虑隐式信息流的情况下,认为变量的状态在赋值后是未污染的。 - 对于形如
a = b + c这样带有二元操作的赋值语句,通常规定如果右端的操作数只要有一个是被污染的,则左端的变量是污染的(除非右端计算结果为常量)。 - 对于和数组元素相关的赋值,如果可以通过静态分析确定数组下标的取值或者取值范围,那么就可以精确地判断数组中哪个或哪些元素是污染的。但通常静态分析不能确定一个变量是污染的,那么就简单地认为整个数组都是污染的。
- 对于包含字段或者包含指针操作的赋值语句,常常需要用到指向分析的分析结果。
- 对于简单的赋值语句,形如
- 控制转移语句。
- 在分析条件控制转移语句时,首先考虑语句中的路径条件可能是包含对污点数据的限制,在实际分析中常常需要识别这种限制污点数据的条件,以判断这些限制条件是否足够包含程序不会受到攻击。如果得出路径条件的限制是足够的,那么可以将相应的变量标记为未污染的。
- 对于循环语句,通常规定循环变量的取值范围不能受到输入的影响。例如在语句
for (i = 1; i < k; i++){}中,可以规定循环的上界 k 不能是污染的。
- 过程调用语句。
- 可以使用过程间的分析或者直接应用过程摘要进行分析。污点分析所使用的过程摘要主要描述怎样改变与该过程相关的变量的污染状态,以及对哪些变量的污染状态进行检测。这些变量可以是过程使用的参数、参数的字段或者过程的返回值等。例如在语句
flag = obj.method(str);中,str 是污染的,那么通过过程间的分析,将变量 obj 的字段 str 标记为污染的,而记录方法的返回值的变量 flag 标记为未污染的。 - 在实际的过程间分析中,可以对已经分析过的过程构建过程摘要。例如前面的语句,其过程摘要描述为:方法 method 的参数污染状态决定其接收对象的实例域 str 的污染状态,并且它的返回值是未受污染的。那么下一次分析需要时,就可以直接应用摘要进行分析。
- 可以使用过程间的分析或者直接应用过程摘要进行分析。污点分析所使用的过程摘要主要描述怎样改变与该过程相关的变量的污染状态,以及对哪些变量的污染状态进行检测。这些变量可以是过程使用的参数、参数的字段或者过程的返回值等。例如在语句
- 赋值语句。
- 代码的遍历。一般情况下,常常使用流敏感的方式或者路径敏感的方式进行遍历,并分析过程中的代码。如果使用流敏感的方式,可以通过对不同路径上的分析结果进行汇集,以发现程序中的数据净化规则。如果使用路径敏感的分析方式,则需要关注路径条件,如果路径条件中涉及对污染变量取值的限制,可认为路径条件对污染数据进行了净化,还可以将分析路径条件对污染数据的限制进行记录,如果在一条程序路径上,这些限制足够保证数据不会被攻击者利用,就可以将相应的变量标记为未污染的。
过程间的分析与数据流过程间分析类似,使用自底向上的分析方法,分析调用图中的每一个过程,进而对程序进行整体的分析。
基于依赖关系的污点分析
在基于依赖关系的污点分析中,首先利用程序的中间表示、控制流图和过程调用图构造程序完整的或者局部的程序的依赖关系。在分析程序依赖关系后,根据污点分析规则,检测 Sink 点处敏感操作是否依赖于 Source 点。
分析程序依赖关系的过程可以看做是构建程序依赖图的过程。程序依赖图是一个有向图。它的节点是程序语句,它的有向边表示程序语句之间的依赖关系。程序依赖图的有向边常常包括数据依赖边和控制依赖边。在构建有一定规模的程序的依赖图时,需要按需地构建程序依赖关系,并且优先考虑和污点信息相关的程序代码。
实例分析
在使用污点分析方法检测程序漏洞时,污点数据相关的程序漏洞是主要关注对象,如 SQL 注入漏洞、命令注入漏洞和跨站脚本漏洞等。
下面是一个存在 SQL 注入漏洞 ASP 程序的例子:
<%
Set pwd = "bar"
Set sql1 = "SELECT companyname FROM " & Request.Cookies("hello")
Set sql2 = Request.QueryString("foo")
MySqlStuff pwd, sql1, sql2
Sub MySqlStuff(password, cmd1, cmd2)
Set conn = Server.CreateObject("ADODB.Connection")
conn.Provider = "Microsoft.Jet.OLEDB.4.0"
conn.Open "c:/webdata/foo.mdb", "foo", password
Set rs = conn.Execute(cmd2)
Set rs = Server.CreateObject("ADODB.recordset")
rs.Open cmd1, conn
End Sub
%>
首先对这段代码表示为一种三地址码的形式,例如第 3 行可以表示为:
a = "SELECT companyname FROM "
b = "hello"
param0 Request
param1 b
callCookies
return c
sql1 = a & c
解析完毕后,需要对程序代码进行控制流分析,这里只包含了一个调用关系(第 5 行)。
接下来,需要识别程序中的 Source 点和 Sink 点以及初始的被污染的数据。
具体的分析过程如下:
- 调用 Request.Cookies("hello") 的返回结果是污染的,所以变量 sql1 也是污染的。
- 调用 Request.QueryString("foo") 的返回结果 sql2 是污染的。
- 函数 MySqlStuff 被调用,它的参数 sql1,sql2 都是污染的。分了分析函数的处理过程,根据第 6 行函数的声明,标记其参数 cmd1,cmd2 是污染的。
- 第 10 行是程序的 Sink 点,函数 conn.Execute 执行 SQL 操作,其参数 cmd2 是污染的,进而发现污染数据从 Source 点传播到 Sink 点。因此,认为程序存在 SQL 注入漏洞